Automatic thesaurus
synonyms for all words in a language
By definition, a thesaurus (plural thesauri, pronounced [-rai]) is a type of dictionary which lists synonyms or words from the same semantic category, e.g. animals, furniture etc.
- beautiful – wonderful, stunning, amazing, good-looking…
- mango – grapefruit, pineapple, banana, papaya, melon…
Thesauri prove very useful to both native speakers as well as language learners when one needs to use a better-fitting word but cannot think of any. In addition, thesaurus databases can be exploited in text search software by allowing the user to automatically include similar words in the search.
Manual vs. automatic
Traditionally, thesauri were built manually. This ensured high quality of the entries but since human labour is expensive, the extent of the thesaurus was limited. There was never enough money for entries for all words in the language. What is more, the quality depended on the expertise and the opinions of the authors for whom it was impossible to be aware of how millions of speakers of the language use each word.
A modern alternative to a man-made thesaurus is an automatically generated thesaurus such as the one found inside Sketch Engine. The entries are generated automatically by analysing a very large collection of text called a corpus. The computation runs without human intervention so the extent of the thesaurus is no longer an issue and a thesaurus can be computed for every word in the language. It can also be rebuilt as frequently as needed to reflect the latest changes in word usage. And most importantly, the content is based on the analysis of language as produced by real users of the language in real situations!
But how can a computer tell which words are synonyms or which words belong to the same category by using computations?
Related
Computing synonyms
Automatic synonym detection draws on the theory of distributional semantics which says, in a nutshell, that words that appear in the same context are similar in meaning. Sketch Engine already has a powerful feature of the word sketch to identify the typical word combinations, i.e. collocations, which play a key role in the computation of the automatically generated thesaurus.
When the user requests a thesaurus for the word beautiful, Sketch Engine will first generate a word sketch for the word which looks like this:

not a complete word sketch, sample only
Then, a word sketch for every other adjective in the corpus will be generated. It looks like this for amazing:

not a complete word sketch, sample only
Scoring the synonyms
It is obvious at first sight that there is a number of collocates which form collocations with both beautiful and amazing. Actually, 56 % of the collocates are typical for both words. On the other hand, a word sketch for mechanical only contains 17 % of collocates which are also the collocates of beautiful.
This score is used to sort the adjectives by their similarity to beautiful and are presented to the user in this order. Realistically, only the top of the thesaurus will contain relevant words. As the user scrolls down, the score decreases in value and the words become less and less relevant.

thesaurus of beautiful based on the 20-billion-word English corpus enTenTen
both columns show good quality
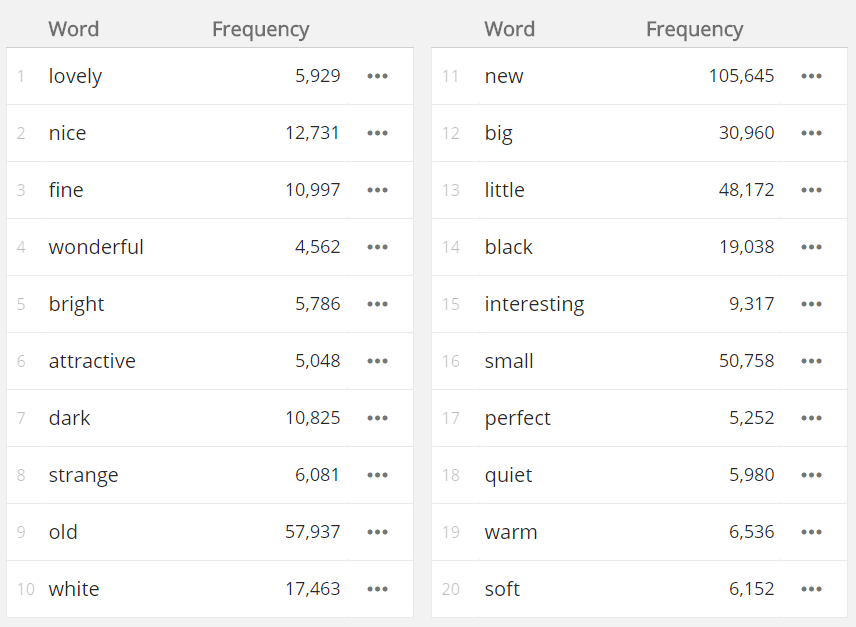
thesaurus of beautiful based on the 96-million-word British National Corpus
less than 1 column of good quality results
The length of the useful top is heavily influenced by the size of the corpus and by the number of occurrences of the words in the corpus. A multi-billion word corpus will easily contain millions of occurrences of the most frequent words which will produce thesaurus entries of dozens of relevant synonyms. A 100-million-word corpus will only produce a handful or relevant words for the most frequent keywords, not to speak about thesauri for less frequent words which will produce hardly any useful result. A 1-million-word corpus is not likely to produce any usable thesaurus.
Corpora and speed
Sketch Engine focusses on producing the largest possible corpora with a target size of billions of words so that the computations produce high-quality results. Generating a thesaurus is a matter of a couple of seconds because the system works with precalculated data. This was the only option to ensure that processing 3 million occurrences of beautiful and 2 million occurrences of amazing will only take a second or two.
Your own automatic thesaurus
Sketch Engine features an automatic corpus building tool that will convert any uploaded text into a corpus with a thesaurus and word sketches (for languages where these features are supported). It will even find relevant texts on the internet and include them in the corpus. No technical skills are required. Users can thus work with thesaurus based on their own data. It is important to bear in mind, however, that the quality is heavily dependent on the corpus size and there is little chance of generating a quality thesaurus from a corpus smaller than 100 million words. The use of the multi-billion-word corpora in Sketch Engine is recommended instead.
Supported languages
Sketch Engine currently hosts 400+ text corpora in 90+ languages. Of them, 63 languages have at least one corpus where word sketches and thesaurus are supported and it is an ongoing project to bring this functionality in for even more languages.
Where to go next?
 https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora
https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592020-07-02 11:31:20Case sensitive and insensitive corpus analysis
https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592020-07-02 11:31:20Case sensitive and insensitive corpus analysis https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase
https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372023-02-09 13:15:00Build a corpus from the web
https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372023-02-09 13:15:00Build a corpus from the web https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392022-08-02 09:03:14POS tags
https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392022-08-02 09:03:14POS tags https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142023-03-28 17:12:15The best term extraction
https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142023-03-28 17:12:15The best term extraction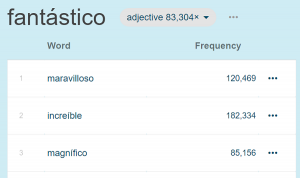 https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182021-01-07 15:00:12Automatic thesaurus
https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182021-01-07 15:00:12Automatic thesaurus https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures
https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502023-01-13 08:57:57Most frequent or most typical collocations?
https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502023-01-13 08:57:57Most frequent or most typical collocations?


