Sketch Engine has a dedicated interface for error-annotated learner corpora. The interface allows users to search specific (in)correct words, errors or corrections by their type (using their codes), or by a combination of the aforementioned criteria. The error analysis is useful for second language acquisition and foreign language learning.
In addition, any metadata included in the corpus can be used in the search and analysed to get information about how learner mistakes are distributed across age groups, proficiency levels, mother tongue, types of test tasks etc.
A correctly constructed learner corpus can provide answers to general questions such as:
- what is the most frequent type of error,
- which age group makes the most mistakes
as well as very specific questions:
- are mistakes related to verb tenses more frequent at B2 or C1 level?
Error analysis interface
A special interface for error-annotated learner corpora is available in the concordance.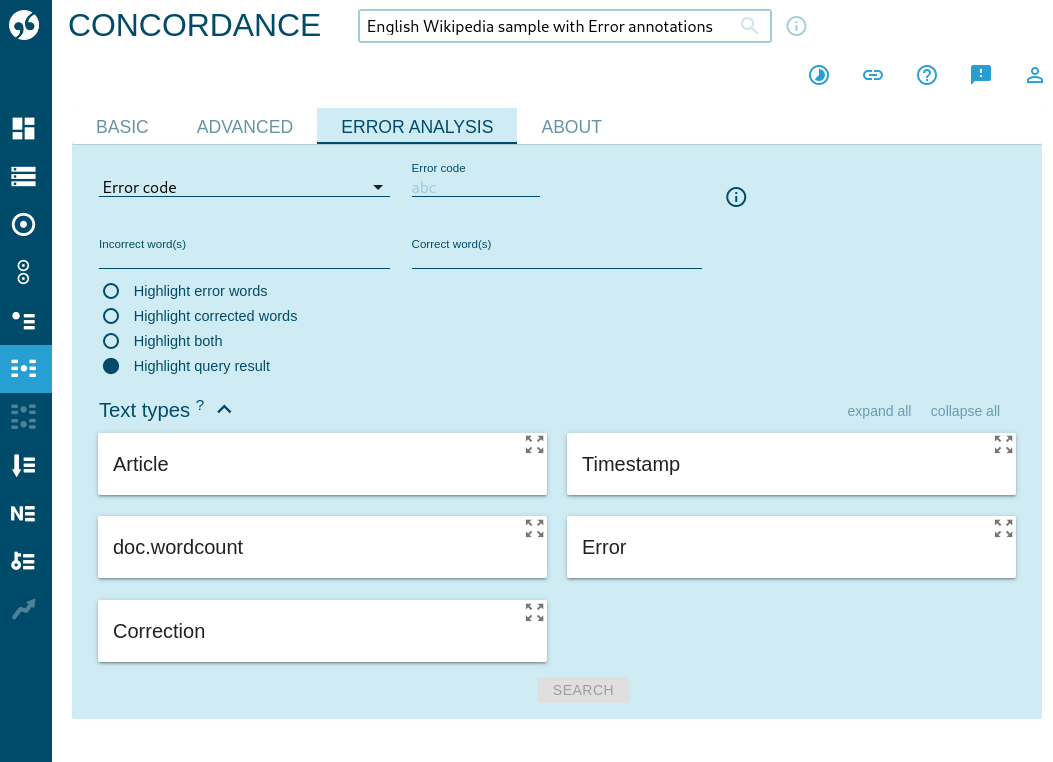
Create an error annotated learner corpus
An error annotated learner corpus is a corpus that contains err structures with type metadata for errors and corr structures with type metadata for corrections. The type of the specific error/correction should always be identical. This is a mandatory format and it ensures that the errors and corrections are processed correctly.
An example of correctly annotated data is:
We attended a <err type="typo">cnoference</err><corr type="typo">conference</corr> in Rio last week. The weather <err type="tense">has been</err><corr type="tense">was</corr>very nice.
<err type="Typo"> cnoference NN cnoference-n </err> <corr type="Typo"> conference NN conference-n </corr>
Both the error and the correction can be empty, indicating that a word was inserted or deleted. A special ===NONE=== token must be inserted. For example:
<err type="DeletedWord"> cnoference NN cnoference-n </err>[[BR]] <corr type="DeletedWord"> ===NONE=== ===NONE=== ===NONE=== </corr>
Set up a learner corpus
Setting up a learner corpus
- create a learner corpus from common text format or vertical format
- open your corpus and click Manage corpus on Dashboard
- select Configure tab
- confirm “I am an expert”
- in the text area, find STRUCTURE “corr” and STRUCTURE “err”
- edit the structure settings with adding directives DISPLAYBEGIN, DISPLAYEND and DISPLAYCLASS as follows
STRUCTURE "err" {
...
DISPLAYTAG 0
DISPLAYBEGIN ''
DISPLAYEND "|"
DISPLAYCLASS "concred"
...
}
STRUCTURE "corr" {
...
DISPLAYTAG 0
DISPLAYBEGIN ""
DISPLAYEND ""
DISPLAYCLASS "concgreen"
...
}
You can also define the color in the RGB notation, e.g. DISPLAYCLASS “#FF0000” for the red color.
7. finally make a concordance and set (in View options) err and corr structures as visible

