enTenTen: Corpus of the English Web
The English Web Corpus (enTenTen) is an English corpus made up of texts collected from the Internet. The corpus belongs to the TenTen corpus family. Sketch Engine currently provides access to TenTen corpora in more than 40 languages. The corpora are built using technology specialized in collecting only linguistically valuable web content.
For detailed information about TenTen corpora, see Common TenTen corpora attributes.
The most recent version of the enTenTen corpus consists of 52 billion words. The texts were downloaded in October–December 2021 and January 2022. The sample texts of the biggest web domains which account for 40% of all corpus texts were checked semi-manually and content with poor quality text and spam was removed.
Part-of-speech tagset and lemmatization
The English Web corpora are part-of-speech tagged with the following English Penn Treebank tagset summary (with Sketch Engine modifications) indicating the part of speech and grammatical category. The corpus texts also contain lemmatization when each word form from the corpus is assigned to its base form (lemma).
The English Web corpora 2008 and 2012 have the English Penn Treebank tagset with earlier Sketch Engine modifications version 1.
Search the English corpus enTenTen
Sketch Engine offers a range of tools to work with this English corpus.
Genre annotation and topic classification
A part of the English Web 2021 corpus contains genre annotation and topic classification. These can be displayed as corpus structures in Concordance or in the Text type Analysis tool. Genres refer to writing styles and are divided into four groups (blog, discussion, fiction, legal, news, reference/encyclopedia) whereas topic classification is inspired by categories used by https://curlie.org/ (formerly dmoz.org) and includes the following topics: arts, beauty & fashion, cars & bikes, culture & entertainment, economy finance & business, games, health, history, hobbies, home family & children, nature & environment, pets & animal, politics & government, religion, science, sex, sports, technology & IT, and travel & tourism.
- genres cover 17.5% of the corpus, i.e. 10.8 billion tokens
- topic classification covers 12.2% of the corpus, i.e. 7.5 billion tokens
Hover over the chart to display a number of tokens of the particular topic.
Overview of English TenTen corpora
This is a list of English Web corpora available in Sketch Engine:
- English Web corpus 2021 (enTenTen21) – 52 billion words, genre annotation and topic classification
- English Web corpus 2020 (enTenTen20) – 36 billion words, genre annotation and topic classification
- English Web corpus 2018 (enTenTen18) – 21.9 billion words
- English Web corpus 2015 (enTenTen15) – 13 billion words (topic classification)
- English Web corpus 2013 (enTenTen13) – 19 billion words
- English Web corpus 2012 (enTenTen12) – 11 billion words
- English Web corpus 2008 (enTenTen08) – 2.7 billion words
enTenTen21 corpus in detail
The chart shows the distribution of the most frequent top-level domains and selected domains of the states where English is the official language. The percentage is based on token coverage.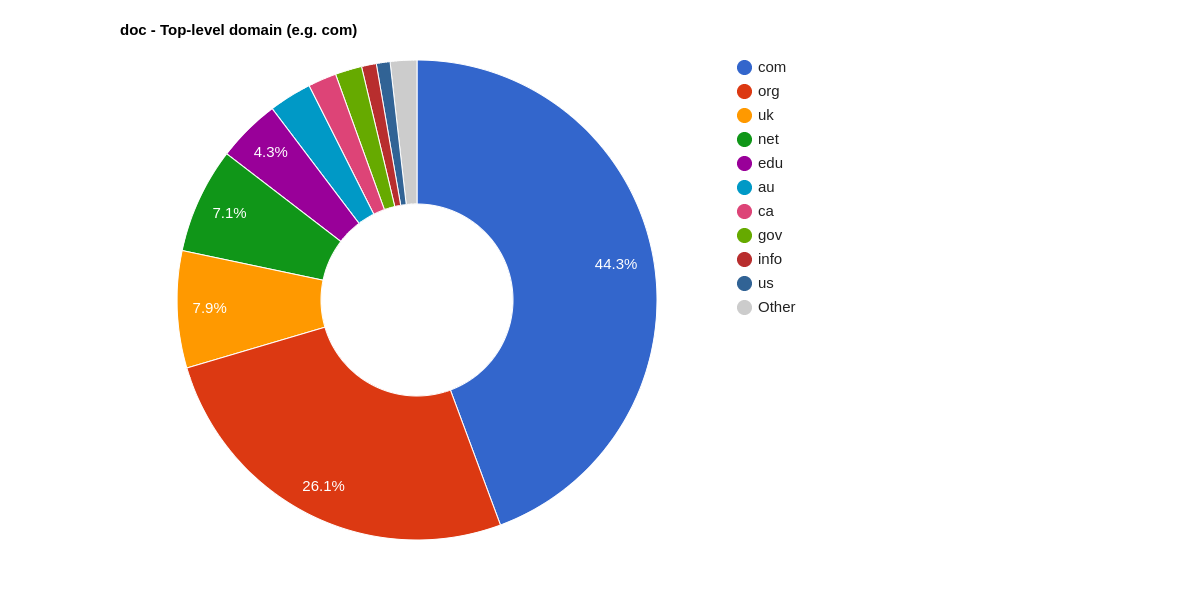
enTenTen21 corpus sizes and preloaded subcorpora
Basic information
| Frequency | |
| Tokens | 61,585,997,113 |
| Words | 52,268,286,493 |
| Sentences | 2,852,972,274 |
| Web pages | 120,252,162 |
Preloaded subcorpora
A list of preloaded subcorpora (based on the top-level domains or genre annotation and topic classification) that are available in the English Web 2021 corpus.
| Subcorpus | Tokens | % of the whole corpus |
| Australian domain .au | 1,083,884,536 | 1.76 |
| Canadian domain .ca | 1,279,711,284 | 2.078 |
| EU domain .eu | 178,200,834 | 0.289 |
| English Wikipedia | 2,781,502,596 | 4.516 |
| Genre Blog | 1,569,499,442 | 2.548 |
| Genre Discussion | 2,103,533,595 | 0.726 |
| Genre Fiction | 1,030,493,934 | 1.673 |
| Genre Legal | 652,370,863 | 1.059 |
| Genre News | 2,420,719,017 | 3.931 |
| Genre Reference/Encyclopedia | 3,047,342,438 | 4.948 |
| Indian domain .in | 275,247,190 | 0.447 |
| Irish domain .ie | 343,876,212 | 0.558 |
| New Zealand domain .nz | 318,843,917 | 0.518 |
| Topic Arts | 191,659,187 | 0.311 |
| Topic Beauty & Fashion | 54,111,137 | 3.06 |
| Topic Cars & Bikes | 293,808,521 | 0.477 |
| Topic Culture & Entertainment | 989,990,028 | 1.607 |
| Topic Economy, Finance & Business | 511,642,058 | 0.831 |
| Topic Education | 235,276,797 | 0.382 |
| Topic Games | 398,193,384 | 0.647 |
| Topic Health | 480,090,118 | 0.78 |
| Topic Hobbies | 103,913,047 | 0.169 |
| Topic Home, Family & Children | 2,447,004,798 | 5.674 |
| Topic Nature & Environment | 1,034,647,808 | 2.399 |
| Topic Pets & Animals | 1,566,713,474 | 3.633 |
| UK domain .uk | 3,466,969,061 | 5.629 |
| US domain .us | 440,106,116 | 0.715 |
Tools to work with the English corpora from the web
A complete set of Sketch Engine tools is available to work with these English corpora to generate:
- word sketch – English collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of English nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
English Web 2021 (enTenTen21)
version ententen21_tt31 (June 2023)
- 52 billion words
- TreeTagger pipeline version 3.1
- cleaning and spam removing
- genre annotation and topic classification
English Web 2020 (enTenTen20)
version ententen20_tt31_1 (April 2022)
- 36.5 billion words
- TreeTagger pipeline version 3.1
- further cleaning and spam removing
- genre annotation and topic classification
version ententen20_tt31 (April 2021)
- 38 billion words (downloaded by SpiderLing in Nov & Dec 2019, Nov & Dec 2020 and Jan 2021)
- TreeTagger pipeline version 3.1
- samples from the biggest web domains were manually checked and content with poor linguistic quality was removed.
English Web 2018 (enTenTen18)
version enTenTen18_tt31 (February 2021)
- 21.9 billion words (Oct & Nov 2018; Jan, Nov & Dec 2017; Nov & Dec 2016; mainly from 2018)
- TreeTagger pipeline version 3.1
- manually checking of biggest web domains (account for 70% of all texts) and content with poor linguistic quality was removed.
English Web 2015 (enTenTen15)
- initial size 28 billion words
version 2 (spring 2017)
- 15 billion words
- TreeTagger pipeline version 2
version enTenTen15_tt31 (March 2020)
- 13 billion words
- TreeTagger pipeline version 3.1
- topic classification (according to dmoz.org)
- depth analysis of spam and its removal including too short documents
English Web 2013 (enTenTen13)
version ententen13_tt2 (2014)
- 19 billion words
- TreeTagger pipeline version 2
version ententen13_tt2_1 (fall 2016)
- new version of word sketch grammar
- dynamic attribute doc.website instead of doc.t2ld
English Web 2012 (enTenTen12)
version ententen12_sample40M (14 June 2012)
- sample of corpus – 3.7 billion words
- crawled by SpiderLing in May 2012
- encoded in UTF-8
version ententen12_1 (2012)
- full corpus – 11 billion words
English Web 2008 (enTenTen08)
version 1 (15 November 2010)
- initial version – 3.3 billion tokens
- crawled by Heritrix in 2008
- encoded in Latin1
Bibliography
TenTen corpora
SUCHOMEL, Vít. Better Web Corpora For Corpus Linguistics And NLP. 2020. Available also from: https://is.muni.cz/th/u4rmz/. Doctoral thesis. Masaryk University, Faculty of Informatics, Brno. Supervised by Pavel RYCHLÝ.
Jakubíček, M., Kilgarriff, A., Kovář, V., Rychlý, P., & Suchomel, V. (2013, July). The TenTen corpus family. In 7th International Corpus Linguistics Conference CL (pp. 125-127).
Suchomel, V., & Pomikálek, J. (2012). Efficient web crawling for large text corpora. In Proceedings of the seventh Web as Corpus Workshop (WAC7) (pp. 39-43).
Genre annotation
SUCHOMEL, Vít. Genre Annotation of Web Corpora: Scheme and Issues. In Kohei Arai, Supriya Kapoor, Rahul Bhatia. Proceedings of the Future Technologies Conference (FTC) 2020, Volume 1. Vancouver, Canada: Springer Nature Switzerland AG, 2021. s. 738-754. ISBN 978-3-030-63127-7. doi:10.1007/978-3-030-63128-4_55.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.

